Conversational AI Analytics Powered by Semantic Intelligence
The tool transforms how teams access console usage insights through a conversational AI experience that enables multi-turn dialogue, progressive refinement, and discovery of unexpected insights. Powered by a proprietary semantic data model achieving 90% query accuracy, the system allows anyone to explore data through natural conversation, ask follow-up questions, and receive narrative summaries that tell the story of what the data reveals—all without SQL knowledge or technical expertise.
Multi-Turn Conversations
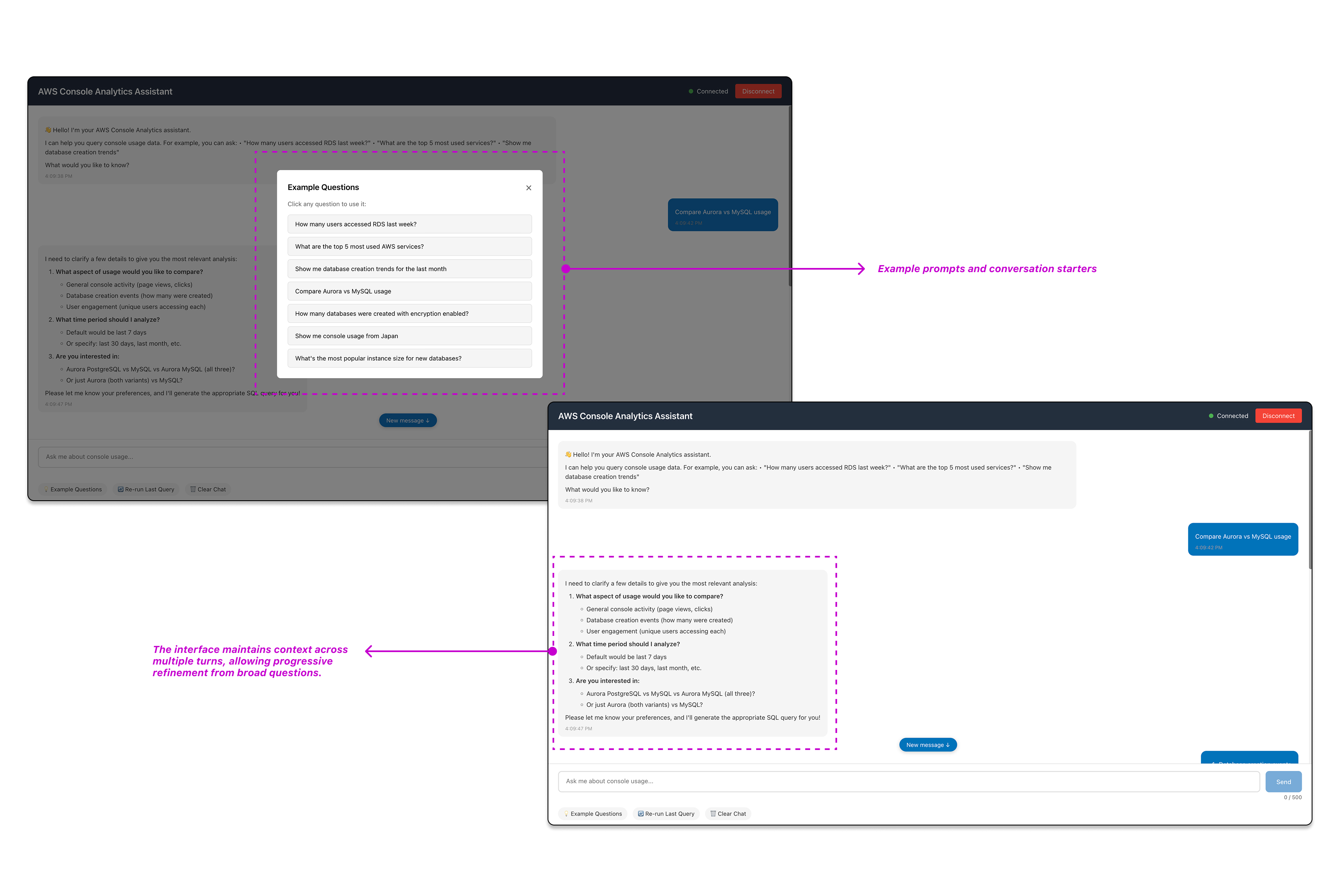
Engage in natural dialogue with context maintained across questions, enabling progressive refinement.
Discovery-Based Exploration
Start broad and refine through dialogue—uncover insights you wouldn't have known to ask for initially.
Semantic Intelligence
Proprietary semantic data model achieves 90% query accuracy with self-correction capabilities.
Data Storytelling
Narrative summaries highlight patterns, trends, and actionable insights—not just raw data.
Key Features
1. Conversational Query Interface with Multi-Turn Dialogue
Users engage in natural conversations about console usage data, asking questions in plain English and receiving guided prompts for follow-up exploration. The interface maintains context across multiple turns, allowing progressive refinement from broad questions to specific insights. Example prompts and conversation starters guide users who don't know exactly what to ask initially, enabling discovery of insights they wouldn't have thought to request.
2. Semantic Data Model with 90% Query Accuracy
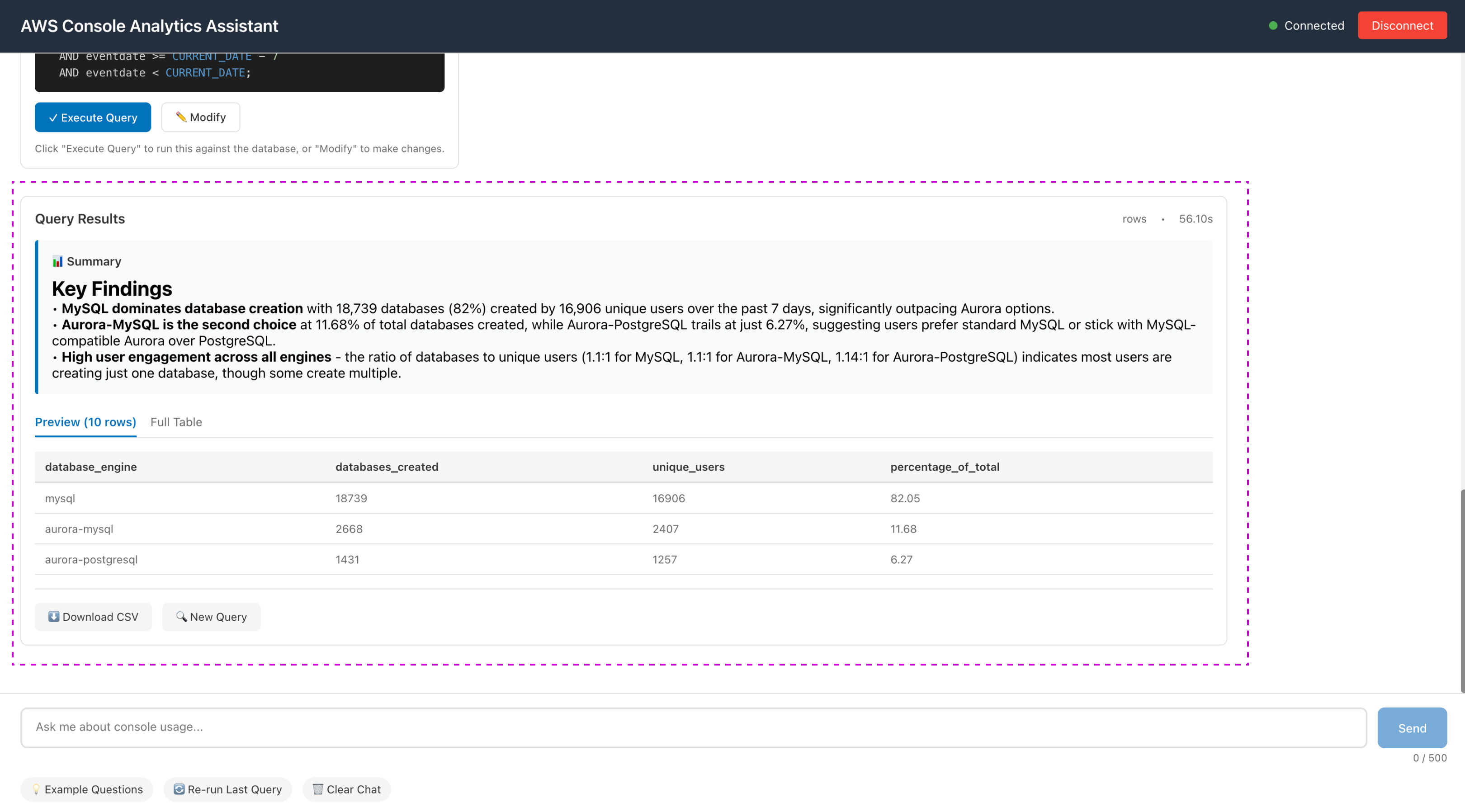
A proprietary semantic data model serves as the critical translation layer between natural language concepts and complex database schema. Through a three-step process (discovery queries, semantic metadata creation, and system prompt integration), the model maps business terms to database elements, handling non-intuitive field relationships and parent-child data structures. This breakthrough achieved 90% query accuracy (from initial <20%) and enabled self-correction capabilities—the agent can recognize when queries return unexpected results and autonomously reformulate its approach.

3. Intelligent Data Storytelling with Narrative Summaries
Rather than presenting raw data tables, the system automatically transforms query results into narrative summaries that tell the story of what the data reveals. The AI identifies patterns, trends, and actionable insights relevant to the user's question, highlighting what matters most and suggesting related avenues for exploration. This approach recognizes that users ask questions because they want answers and understanding—not because they want to manually analyze spreadsheets. The combination of accurate data retrieval and intelligent interpretation creates true value.
The Semantic Data Model Breakthrough
From 20% to 90% Query Accuracy
The proprietary semantic data model is the core innovation that makes accurate natural language to SQL translation possible. This translation layer maps how users think about data (in business terms) to how data is actually stored (in technical database structures).
Three-Step Development Process:
Discovery Queries
Generated exploratory queries against the database and exported results to understand the actual data structure, relationships, and field meanings.
Semantic Metadata Translation
Created a comprehensive semantic metadata file mapping natural language concepts to database elements, including table definitions, field descriptions, parent-child relationships, and business logic rules.
Knowledge Base Integration
Incorporated the semantic metadata file and sample queries into the system prompt powering the conversational agent, giving it robust knowledge for understanding user requests.
Impact: Query accuracy improved from less than 20% to 90%, and the agent gained self-correction capabilities—it can now recognize when a query doesn't return expected results and autonomously reformulate its approach. This semantic layer is what enables non-technical users to access technical data.
Technical Architecture
Conversational Interface Layer
React-based chat interface that maintains conversation context across multiple turns and displays both raw data and AI-generated narrative insights
AI Processing Layer
Amazon Bedrock agent with carefully engineered system prompt containing the semantic data model, enabling intent detection, SQL generation, and self-correction
Data Layer
Amazon Redshift with optimized query execution and result formatting, mapped through the semantic data model for accuracy
Technologies: React, Amazon Bedrock, Amazon Redshift, SQL, Semantic metadata architecture, System prompt engineering
Design Impact: By combining conversational AI, a proprietary semantic data model achieving 90% accuracy, and intelligent data storytelling, the tool eliminates every technical barrier that previously prevented non-technical team members from accessing console usage insights. The result is true democratization of data analytics through discovery-based exploration.